



版权说明:本文档由用户提供并上传,收益归属内容提供方,若内容存在侵权,请进行举报或认领
文档简介
1、检索词:人工智能(artificial intelligence)在web of science上面使用人工智能检索词,限定主题检索,时间范围从1950-2017年,得到了上万条结果,所以我以被引量降序排列为条件,选取了前450篇文献,下载在本地文件夹中。1.导入savedrecs.txt文件2. 将.txt文件转成.tx2文件,点选.txt文件,使其变为蓝底,选择在“Edit doc file”栏下的“Replace line feed with carriage return”选项,选择“确定”选项、选择“是”选项、选择“是”选项。得到如下图3. 将.tx2文件转成.doc文件,点选该.t
2、x2文件,使其会变为蓝底,选择在“Misc”栏下的“Convent to Dialog format”选项卡下面的“Convent from Web of Science”选项,选择“确定”选项。得到如下图选择作者(author)4. 选择作者(author)进行频次分析,在Old Tag中输入au(不区分大小写),在中选择Any;separated field 划分方式,点击Prep。得到如下图5.重命名,为防止文件名相同的话被覆盖,在“Type new file name here”下面的文本框中输入“author”,选择“file”选项卡下面的“Renamefile”,选择“确定”选项,
3、即可重命名。如下图所示分析:得到的两列结果,第二列代表文献作者,第一列代表文献作者出现次数(升序排列),第一列中有相同数字的,如:2、6、9等,这代表这些作者出现在同一篇文献,比如出现两次2,说明有2个作者写了在“第2篇”文献。6. 对含有作者(au)的out文件分析,先点选需要转换的out文件,使其 out文件变为蓝底,再在中选择“Whole string”,然后再勾选“Sort descending”表示对结果进行降序排列,最后点击“Start”。得到如下图分析:得到的两列结果,第二列代表文献作者,第一列代表文献作者出现次数(降序排列),有相同的出现次数,表示这些作者写的文献数量相同(45
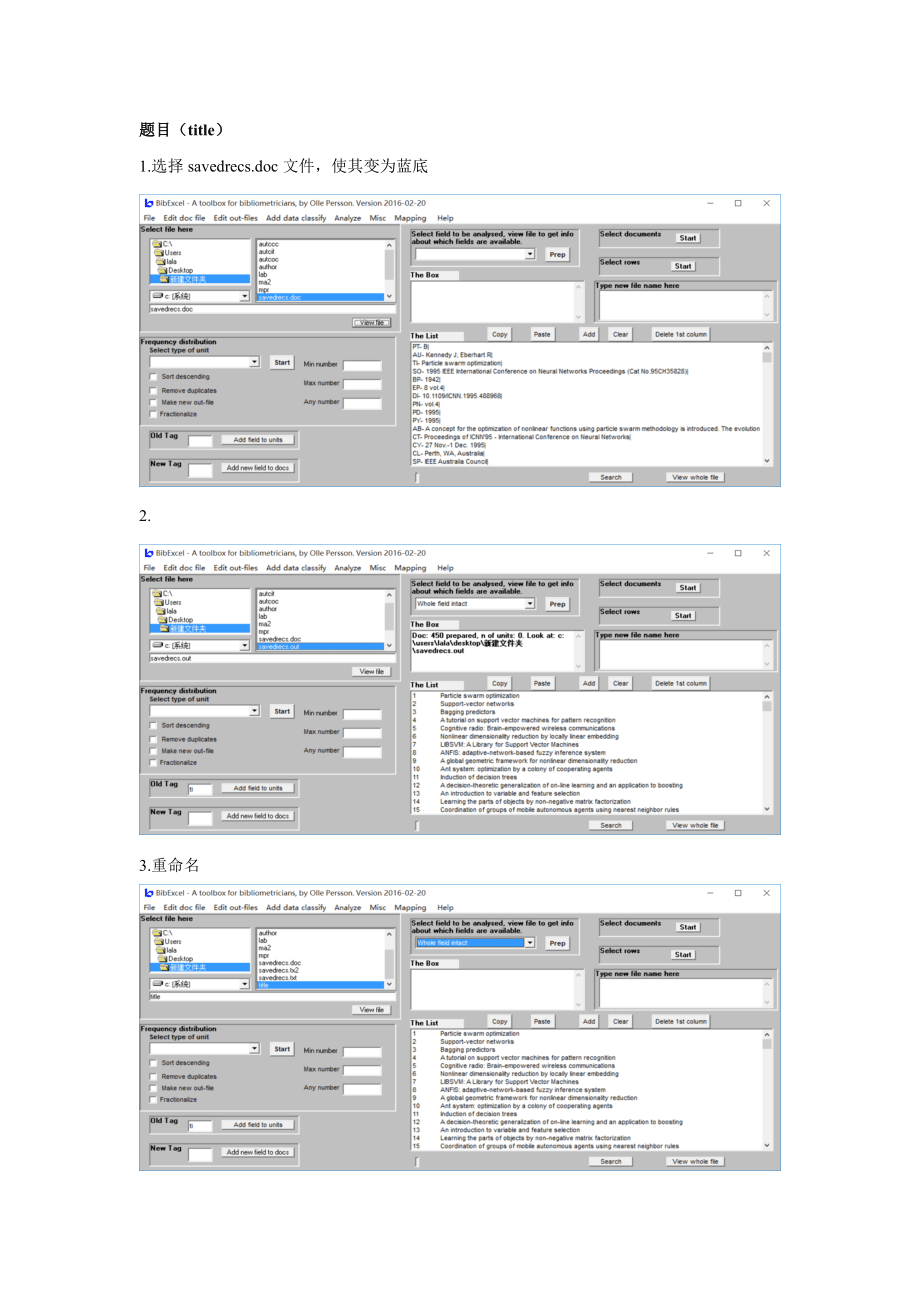
4、0篇中),在这里最高的是6次的那个作者。题目(title)1.选择savedrecs.doc文件,使其变为蓝底2.3.重命名分析:在题目条件中,没有相同的结果4.对题目文件进行分析 分析:每个题目出现次数都是一次。对出版年份(py)分析选择.doc文件,在Old Tag中输入py,在中选择“Whole filed intact”,如下图: 点击“Prep”,选择“确定”,选择“No”,如下图:重命名对out文件进行分析,点选publish_year文件,使其 out文件变为蓝底,再在中选择“Whole string”,然后再勾选“Sort descending”表示对结果进行降序排列,最后点击
5、“Start”,在就产生了一个与原out文件相同名称的cit文件,如下图所示:分析:该文件会形成两列,第1列表示一个publish_yesr在所有文章中出现的次数,从大到小排列,第2列表示publish_year,本文件中文献出版最多的是1997年,共出版了30次。将cit文件中的所有数据拷贝到Excel中,绘制折线图,如下图:450篇文献是按照被引量降序排列选出的,虽然这个时间分布曲线图是不全面的,但我们还是可以从图中看出一些规律,人工智能这个概念最早是在20世纪60年代提出的,在上升一段时间后到达一个峰值会下降到一个低谷,是一个周期性的发展,在80年代-20世纪初的文献被引最多。关键词(d
6、e)共线分析,我截取的数据中没有de项,所以我使用作者(author)代替,但操作步骤和分析方法是一样的。点选.doc文件,使其变成蓝底,在Old Tag中输入au,在中选择Any;separated field 划分方式,点击Prep。得到如下图2. 重命名,为防止文件名相同的话被覆盖,在“Type new file name here”下面的文本框中输入“author”,选择“file”选项卡下面的“Renamefile”,选择“确定”选项,即可重命名。如下图所示3. 对含有作者(au)的out文件分析,先点选需要转换的out文件,使其 out文件变为蓝底,再在中选择“Whole stri
7、ng”,然后再勾选“Sort descending”表示对结果进行降序排列,最后点击“Start”。得到如下图4.对author的cit文件里面“列表栏”中选择出现超过2次的人的名单,再选择“Analyze”选项卡下面的“Co-occurrence”选项里面的“Select Units vialist box”,然后再选中author的out文件,选择“Analyze”选项卡下面的“Co-occurrence”选项里面的“Make pairs vialist box”,在弹出的选项框中选择“否”,再选择“确定”,得到一个author共现的coc文件,如下图:分析:出现三列(一列数字,两列人名),第一列数字代表出现次数,人名是合作作者名字。6.点选author的coc文件,使其变为蓝底;再选择“Analyze”选项卡下面的“List Units inpairs”选项,在弹出的对话框中,选择“确定”,就会产生一个统计作者在coc文件出现次数的ccc文件,如下图:7.先点选author的ccc文件并打开,再选择author的coc文件,使其coc文件变为蓝底;再选择“Analyze”选项卡下面的“Make a matrix for MDSetc”选项,弹出的对话框中选择“确定”,最终会产生三个文件,ma2文件表示
温馨提示
- 1. 本站所有资源如无特殊说明,都需要本地电脑安装OFFICE2007和PDF阅读器。图纸软件为CAD,CAXA,PROE,UG,SolidWorks等.压缩文件请下载最新的WinRAR软件解压。
- 2. 本站的文档不包含任何第三方提供的附件图纸等,如果需要附件,请联系上传者。文件的所有权益归上传用户所有。
- 3. 本站RAR压缩包中若带图纸,网页内容里面会有图纸预览,若没有图纸预览就没有图纸。
- 4. 未经权益所有人同意不得将文件中的内容挪作商业或盈利用途。
- 5. 人人文库网仅提供信息存储空间,仅对用户上传内容的表现方式做保护处理,对用户上传分享的文档内容本身不做任何修改或编辑,并不能对任何下载内容负责。
- 6. 下载文件中如有侵权或不适当内容,请与我们联系,我们立即纠正。
- 7. 本站不保证下载资源的准确性、安全性和完整性, 同时也不承担用户因使用这些下载资源对自己和他人造成任何形式的伤害或损失。
最新文档
- 井维修合同标准文本
- 出差工作合同标准文本
- 农村安装路灯用工合同标准文本
- 2025职工劳动合同期满评审表
- 保理抵押合同样本
- 水资源保护与生态恢复的协同发展计划
- 职场压力管理的技巧计划
- 中标合同样本字体格式
- 2025环境影响评价技术咨询合同
- 共同创业股东合同样本
- 【16G101】钢筋平法图集三维速查2020 88P
- 《践行社会主义核心价值观》主题班会教案
- 消防应急组织架构图
- TJSTJXH 6-2022 城市轨道交通工程盾构管片预制及拼装技术标准
- 信息技术2.0微能力:小学五年级道德与法治上(第三单元)守望相助-中小学作业设计大赛获奖优秀作品-《义务教育道德与法治课程标准(2022年版)》
- 新教材人教版高中化学选择性必修三全册知识点梳理
- 基于嵌入式系统的无线传感器网络的应用研究
- Q∕SY 08124.23-2017 石油企业现场安全检查规范 第23部分:汽车装卸车栈台
- 有机化学 第十三章 有机含氮化合物
- 青岛版小学二年级数学下册《解决问题(信息窗3)》参考课件(共12张PPT)
- 中华护理学会科研课题申请书
评论
0/150
提交评论