



版权说明:本文档由用户提供并上传,收益归属内容提供方,若内容存在侵权,请进行举报或认领
文档简介
python课程设计——当当⽹Python图书数据分析⼀、数据获取本次项⽬数据来源为爬⾍获取,⽬标为为当当⽹上关于python的书籍爬⾍主要思路:通过观察当当⽹,观察结构,选⽤适合的⽅法。先进⾏单页的数据爬取,再进⾏多页爬取;解析⽅法为xpath⽅法,爬取⽬标为:书名、价格、作业、出版社、出版时间、商品链接、评论数量;最后将爬取的数据保存到csv⽂件当中。爬⾍代码如下:
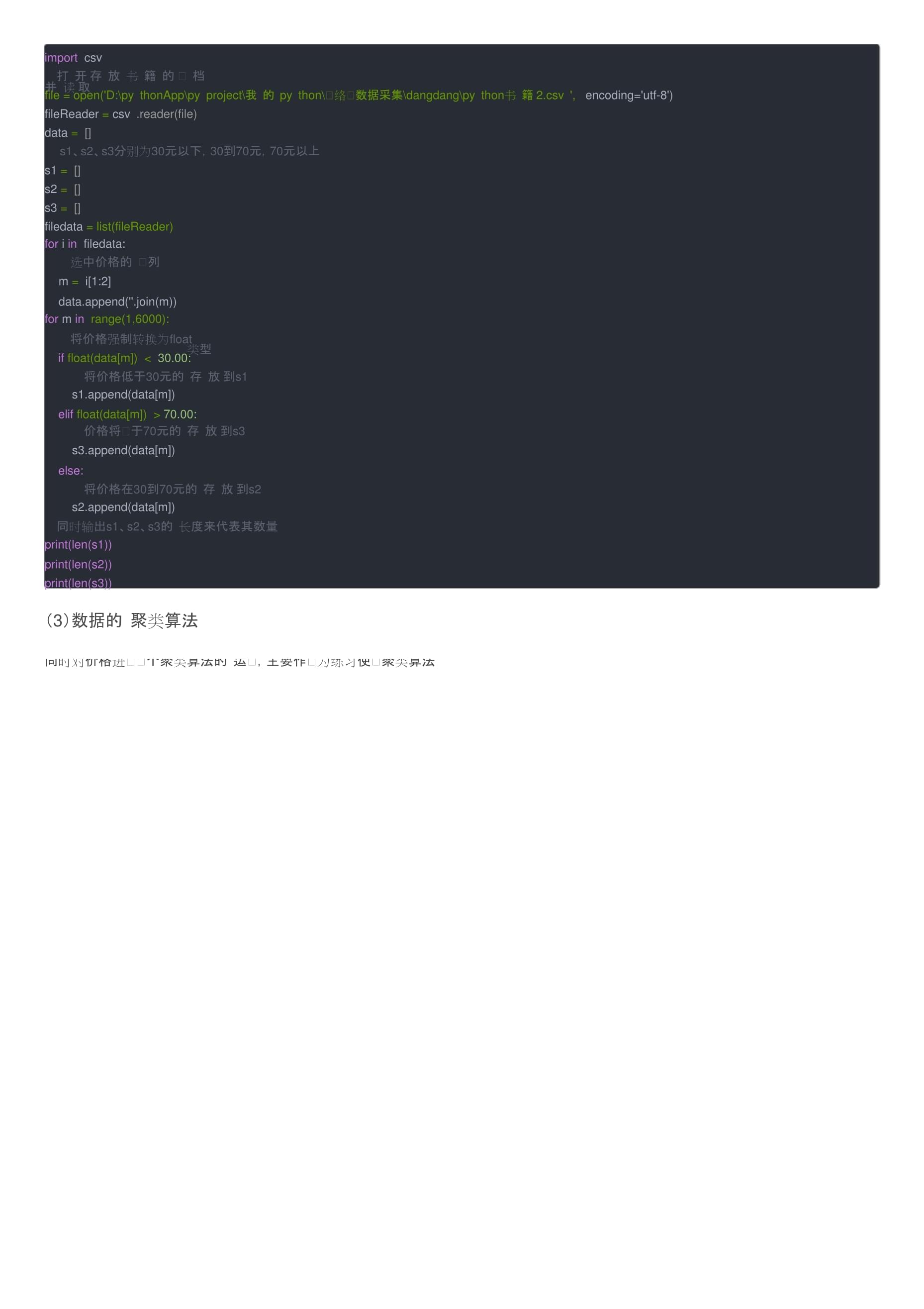
importrequestsfromlxmlimportetreeimportreimportcsvdefget_page():#数据的多页爬取,经过观察,所有页⾯地址中,有⼀个唯⼀的参page_index数发⽣改变#通过对参数page_indexfor循环,遍历每⼀页的页⾯,实现多页爬取forpageinrange(1,101):的url='/?key=python&act=input&page_index=1'+str(page+1)+'#J_tab'headers={'User-Agent':'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36''(KHTML,likeGecko)Chrome/96.0.4664.110Safari/537.36'}response=requests.get(url=url,headers=headers)parse_page(response)#可以在操作页⾯实时观察爬取的进度print('page%s'%page)defparse_page(response):#通过etree将图书的七项信息封装为⼀条数据,保存到data列表当中tree=etree.HTML(response.text)li_list=tree.xpath('//ul[@class="bigimg"]/li')forliinli_list:data=[]try:#通过xpath的⽅法对所需要的信息进⾏解析#1、获取书的标题并添加到列表中,title=li.xpath('./a/@title')[0].strip()data.append(title)#2、获取价格并添加到列表中,price=li.xpath('./p[@class="price"]/span[1]/text()')[0]data.append(price)#3、获取作者并添加到列表中,author=''.join(li.xpath('./p[@class="search_book_author"]/span[1]//text()')).strip()data.append(author)#4、获取出版社publis=''.join(li.xpath('./p[@class="search_book_author"]/span[3]//text()')).strip()data.append(publis)#5、获取出版时间并添加到列表中,time=li.xpath('./p[@class="search_book_author"]/span[2]/text()')[0]pub_time=re.sub('/','',time).strip()data.append(pub_time)#6、获取商品链接并添加到列表中,commodity_url=li.xpath('./p[@class="name"]/a/@href')[0]data.append(commodity_url)#7、获取评论数量,并添加到列表中comment=li.xpath('./p[@class="search_star_line"]/a/text()')[0].strip()data.append(comment)except:passsave_data(data)defsave_data(data):writer.writerow(data)defmain():key='python书籍222'#input('Pleaseinputkey:')get_page(key)#将所有的数据储存到csv⽂件当中fp=open('python书籍3.csv','w',encoding='utf-8-sig',newline='')writer=csv.writer(fp)header=['书名','价格','作者','出版社','出版时间','商品链接','评论数量']writer.writerow(header)main()fp.close()爬⾍部分结果展⽰:⼆、数据整理分析本项⽬对价格、出版社以及评论进⾏分析1、价格(1)数据预处理通过观察爬取下来的数据发现,部分数据存在空值,影响分析,所以多价格列进⾏简单的数据预处理操作,将有空值的整条数据删除利⽤pandas库中的null函数查询是否有空值,有空值就将其整条数据删除importpandasaspd#读取⽂件df=pd.read_csv(r'D:\pythonApp\pyproject\我的python\⽹络⼤数据采集\dangdang\python书籍.csv')#对价格列进⾏操作index=df['价格'].notnull()df=df[index]#将处理好的⽂件保存为python书籍2df.to_csv(r'D:\pythonApp\pyproject\我的python\⽹络⼤数据采集\dangdang\python书籍2.csv')(2)数据分类操作然后对价格列进⾏分类,将其分为三个类别,分别为价格在30元以下的,价格在30元到70元之间的,价格在70元以上的,注意数据的数据的类型是什么,是否需要类型的转换。importcsv#打开存放书籍的⽂档并读取file=open('D:\pythonApp\pyproject\我的python\⽹络⼤数据采集\dangdang\python书籍2.csv',encoding='utf-8')fileReader=csv.reader(file)data=[]#s1、s2、s3分别为30元以下,30到70元,70元以上s1=[]s2=[]s3=[]filedata=list(fileReader)foriinfiledata:#选中价格的⼀列m=i[1:2]data.append(''.join(m))forminrange(1,6000):#将价格强制转换为float类型iffloat(data[m])<30.00:#将价格低于30元的存放到s1s1.append(data[m])eliffloat(data[m])>70.00:#价格将⾼于70元的存放到s3s3.append(data[m])else:#将价格在30到70元的存放到s2s2.append(data[m])#同时输出s1、s2、s3的长度来代表其数量print(len(s1))print(len(s2))print(len(s3))(3)数据的聚类算法同时对价格进⾏⼀个聚类算法的运⽤,主要作⽤为练习使⽤聚类算法importjiebaimportcollectionsimportwordcloudimportmatplotlib.pyplotasplt#存放去停⽤词stopword_list=[]#存放分词object_list=[]#去停⽤词forwordinopen("D:\pythonApp\pyproject\我的python\⽹络⼤数据采集\dangdang\stopwords.txt",'rb'):stopword_list.append(word.strip())#⽂本分词fn=open("D:\pythonApp\pyproject\我的python\⽹络⼤数据采集\dangdang\Comment_Data.txt","rb").read()seg_list_exaut=jieba.cut(fn)foriinseg_list_exaut:ifi.encode("utf-8")notinstopword_list:object_list.append(i)#词频统计、排序word_counts=collections.Counter(object_list)word_counts_top10=word_counts.most_common(10)print(word_counts_top10)#词图云展⽰wc=wordcloud.WordCloud(font_path=r'C:\Windows\Fonts\simhei.ttf',background_color="white",margin=5,width=1000,height=800,max_words=1000,max_font_size=200)wc.generate_from_frequencies(word_counts)wc.to_file('DangDangWang_WordCloud_show.jpg')plt.imshow(wc)plt.axis("off")plt.show()聚类算法的结果2、出版社对于出版社的分析主要为统计出版社的数量,并对每个出版社出版关于python的书籍的数量进⾏统计分析,因此需要对数据进⾏去重处理(1)数据预处理数据的去重处理file=open('D:\pythonApp\pyproject\我的python\⽹络⼤数据采集\dangdang\python书籍.csv',encoding='utf-8')fileReader=csv.reader(file)filedata=list(fileReader)data=[]foriinfiledata:#数据表第四列为出版社t=i[3:4]data.append(''.join(t))#去重punlish_Number=len(set(data))print('出版社共'+str(punlish_Number)+'个')punlish_data=list(set(data))(2)统计对出版社的种类以及数量进⾏统计#统计出版社dict={}foriindata:dict[i]=dict.get(i,0)+1#输出所有的出版社以及个数print(dict)#print(len(dict))结果展⽰由结果可知出版社共有50个,选取前⼗名的出版社进⾏保存3、评论数量通过观察处理,发现存在很多数据没有评论,因此需要进⾏预处理对没有评论数量的数据进⾏删除操作importpandasaspd#读取⽂件df=pd.read_csv(r'D:\pythonApp\pyproject\我的python\⽹络⼤数据采集\dangdang\python书籍.csv')#对价格列进⾏操作index=df['评论数量'].notnull()df=df[index]df.to_csv(r'D:\pythonApp\pyproject\我的python\⽹络⼤数据采集\dangdang\python书籍3.csv')结果展⽰对评论数量进⾏排序,选取评论数量前⼗的书籍进⾏展⽰三、数据可视化1、价格结果展⽰代码importmatplotlib.pyplotasplt#设置中⽂显⽰plt.rcParams['font.sans-serif']='SimHei'plt.rcParams['axes.unicode_minus']=Falselabels='30元以下','30到70元','70元以上'fraces=[125,3427,2447]#使画出来的图形为标准圆plt.axes(aspect=1)#突出分离出数量最多的第⼆部分explode=[0,0.1,0]colors=['skyblue','pink','yellow']plt.pie(x=fraces,labels=labels,colors=colors,#显⽰⽐例autopct='%0f%%',explode=explode,#显⽰阴影,使图形更加美观shadow=True)plt.show()2、出版社结果展⽰代码importmatplotlib.pyplotasplt#设置中⽂显⽰plt.rcParams['font.sans-serif']='SimHei'plt.rcParams['axes.unicode_minus']=Falsenum_list=[1530,1390,1255,625,194,100,99,95,93,93]name_list=['⼈民邮电出版社','机械⼯业出版社','电⼦⼯业出版社','清华⼤学出版社','北京⼤学出版社','中国⽔利⽔电出版社','中国铁道出版社','东南⼤学出版社','华中科技⼤学出版社','重庆⼤学出版社']plt.barh(range(len(num_list)),num_list,align="center",#设置标签tick_label=name_list,)plt.title('出版社前⼗柱状图')plt.show()3、评论本项分析选取评论数量第⼀的书,将其所有的评论进⾏了爬取,并制作词云图进⾏展⽰评论爬取代码file=open('D:\pythonApp\pyproject\我的python\⽹络⼤数据采集\dangdang\python书籍4.csv',encoding='utf-8')fileReader=csv.reader(file)filedata=list(fileReader)books_number=[]foriinfiledata:t=(i[5:6])books_number.append(''.join(t))print(books_number)forjinrange(1,6):foriinrange(1,21):url='/index.php?r=comment%2Flist&productId='+books_number[j]+\'&categoryPath=01.54.06.19.00.00&mainProductId=25580336&mediumId=0&pageIndex='+str(i)+\headers={'&sortType=1&filterType=1&isSystem=1&tagId=0&tagFilterCount=0&template=publish''User-Agent':'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/''87.0.4280.88Safari/537.36'}print(url)req=urllib.request.Request(url,headers=headers)response=urllib.request.urlopen(req)unicodester=json.load(response)html=unicodester["data"]["list"]["html"]pattern=pile('<span><ahref.*?>(.*?)<\/a><\/span>',re.S)comments=re.findall(pattern,html)print("正在爬取第"+str(i)+"页评论")withopen('Comment_Data.txt','a')astxt:txt.write(str(comments)+"\n")结果展⽰因为我的停⽤词没有筛选好,导致制作出来的词云图不够规范,⼤家可以根据⾃⼰的需要对停⽤词进⾏添加代码importjiebaimportcollectionsimportwordcloudimportmatplotlib.pyplotasplt#存放去停⽤词stopword_list=[]#存放分词object_list=[]#去停⽤词forwordinopen("D:\pythonApp\pyproject\我的
温馨提示
- 1. 本站所有资源如无特殊说明,都需要本地电脑安装OFFICE2007和PDF阅读器。图纸软件为CAD,CAXA,PROE,UG,SolidWorks等.压缩文件请下载最新的WinRAR软件解压。
- 2. 本站的文档不包含任何第三方提供的附件图纸等,如果需要附件,请联系上传者。文件的所有权益归上传用户所有。
- 3. 本站RAR压缩包中若带图纸,网页内容里面会有图纸预览,若没有图纸预览就没有图纸。
- 4. 未经权益所有人同意不得将文件中的内容挪作商业或盈利用途。
- 5. 人人文库网仅提供信息存储空间,仅对用户上传内容的表现方式做保护处理,对用户上传分享的文档内容本身不做任何修改或编辑,并不能对任何下载内容负责。
- 6. 下载文件中如有侵权或不适当内容,请与我们联系,我们立即纠正。
- 7. 本站不保证下载资源的准确性、安全性和完整性, 同时也不承担用户因使用这些下载资源对自己和他人造成任何形式的伤害或损失。
最新文档
- 汽车和食品合作协议书
- 无纸化商户签约协议书
- 课程置换协议书
- 联通授权协议书
- 自驾免责协议书
- 药厂授权协议书
- 平台店铺代运营协议书
- 药品三方协议书
- 豪车合成协议书
- 旧房屋顶翻合同协议书
- 病假医疗期申请单(新修订)
- 钻孔桩钻孔记录表(旋挖钻)
- 660MW机组金属监督项目
- JBK-698CX淬火机数控系统
- ZJUTTOP100理工类学术期刊目录(2018年版)
- 心理学在船舶安全管理中的应用
- JJF(鄂) 90-2021 电子辊道秤校准规范(高清版)
- 超星尔雅学习通《今天的日本》章节测试含答案
- 餐饮量化分级
- 三一重工SCC2000履带吊履带式起重机技术参数
- [精品]GA38-2004《银行营业场所风险等级和防护级别的规定》
评论
0/150
提交评论