



版权说明:本文档由用户提供并上传,收益归属内容提供方,若内容存在侵权,请进行举报或认领
文档简介
1、聚类分析:基本概念和算法What is Cluster Analysis?l Finding groups of objects such that the objects in a group will be similar (or related) to one another and different from (or unrelated to) the objects in other groupsInter-cluster distances areizedIntra-cluster distances are minimized6/12/2010#Applications of
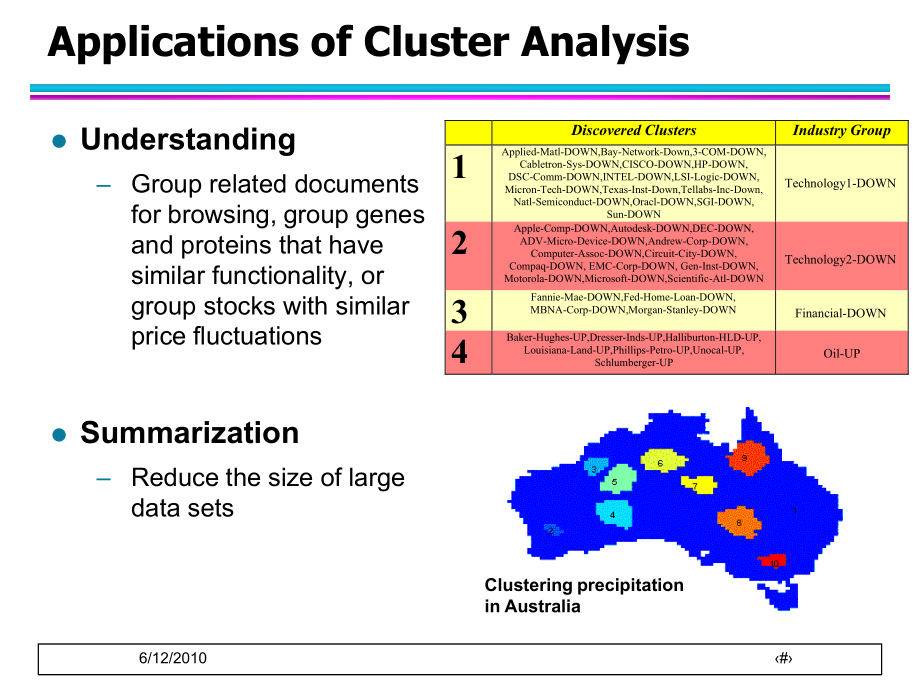
2、Cluster Analysisl UnderstandingGroup related documents for browsing, group genes and proteins that have similar functionality, or group stocks with similar price fluctuationsl SummarizationReduce the size of large data setsClustering precipitation in Australia6/12/2010#Discovered ClustersIndustry Gr
3、oup1Applied-Matl-DOWN,Bay-Network-Down,3-COM-DOWN, Cabletron-Sys-DOWN,CISCO-DOWN,HP-DOWN,DSC-Comm-DOWN,INTEL-DOWN,LSI-Logic-DOWN,Micron-Tech-DOWN,Texas-Inst-Down,Tellabs-Inc-Down, Natl-Semiconduct-DOWN,Oracl-DOWN,SGI-DOWN, Sun-DOWNTechnology1-DOWN2Apple-Comp-DOWN,Autodesk-DOWN,DEC-DOWN, ADV-Micro-De
4、vice-DOWN,Andrew-Corp-DOWN, Computer-Assoc-DOWN,Circuit-City-DOWN,Compaq-DOWN, EMC-Corp-DOWN, Gen-Inst-DOWN, Motorola-DOWN,Microsoft-DOWN,Scientific-Atl-DOWNTechnology2-DOWN3Fannie-Mae-DOWN,Fed-Home-Loan-DOWN, MBNA-Corp-DOWN,Morgan-Stanley-DOWNFinancial-DOWN4Baker-Hughes-UP,Dresser-Inds-UP,Halliburt
5、on-HLD-UP, Louisiana-Land-UP,Phillips-Petro-UP,Unocal-UP, Schlumberger-UPOil-UPApplications of Cluster Analysisl Understanding:conceptually meaningful groups ofobjects that share common characteristics are potential classesBiology: a taxonomy of all living things; groups of genes with similar functi
6、onsInformation Retrieval: group results of a query to a searchengine into a small number of clusters for each aspectClimate: patterns in the atmosphere and oceanPsychology and Medicine: different subcategories of illnesses and conditions (健康状态,such as depression); spatial and temporal distribution o
7、f a diseaseBusiness: customer grouping and marketing6/12/2010#Applications of Cluster Analysisl Utility:finding the most representative clusterprototypes for further data analysis and processingSummarization: applying algorithms to a reduced data set consisting only of cluster prototypesCompression:
8、 each object is represented by the index of the prototype of the cluster than it belongs toEfficiently Finding Nearest Neighbors: only need to compute the distance to objects in nearby clusters based on prototype distance6/12/2010#Notion of a Cluster can be AmbiguousHow many clusters?Six ClustersTwo
9、 ClustersFour Clusters6/12/2010#Related Techniquesl Classificationsupervisedunsupervisedl Segmentation: split an image into segmentsl Partitioning: divide graph into subgraphs6/12/2010#Types of Clusteringsl A clustering is a set of clustersl Important distinction between hierarchical and partitional
10、 sets of clustersl Partitional Clustering A division data objects into non-overlapping subsets (clusters) such that each data object is in exactly one subsetl Hierarchical clustering A set of nested clusters organized as a hierarchical tree6/12/2010#Partitional ClusteringOriginal PointsA Partitional
11、 Clustering6/12/2010#Hierarchical Clusteringp1p3p4p2p1p2p3 p4Traditional Hierarchical ClusteringTraditional Dendrogramp1p3p4p2p1 p2p3 p4Non-traditional Hierarchical ClusteringNon-traditional Dendrogram6/12/2010#Other Distinctions Between Sets of Clustersl Exclusive versus non-exclusive In non-exclus
12、ive clusterings, points may belong to multipleclusters. Can represent multiple classes or border pointsl Fuzzy versus non-fuzzyIn fuzzy clustering, a point belongs to every cluster with someweight between 0 and 1Weights must sum to 1Probabilistic clustering has similar characteristicsl Partial versu
13、s complete In some cases, we only want to cluster some of the datal Heterogeneous versus homogeneous Cluster of widely different sizes, shapes, and densities6/12/2010#Types of Clustersl Well-separated clustersl Center-based clustersl Contiguous(邻接) clustersl Density-based clustersl Property or Conce
14、ptuall Described by an Objective Function6/12/2010#Types of Clusters: Well-Separatedl Well-Separated Clusters:A cluster is a set of points such that any point in a cluster is closer (or more similar) to every other point in the cluster than to any point not in the cluster.3 well-separated clusters6/
15、12/2010#Types of Clusters: Center-Basedl Center-basedA cluster is a set of objects such that an object in a cluster is closer (more similar) to the “center” of a cluster, than to the center of any other clusterThe center of a cluster is often a centroid, the average of all the points in the cluster,
16、 or a medoid, the most “representative” point of a cluster4 center-based clusters6/12/2010#Types of Clusters: Contiguity-Basedl Contiguous Cluster (Nearest neighbor or Transitive)A cluster is a set of points such that a point in a cluster is closer (or more similar) to one or more other points in th
17、e cluster than to any point not in the cluster.8 contiguous clusters6/12/2010#Types of Clusters: Density-Basedl Density-basedA cluster is a dense region of points, which is separated by low-density regions, from other regions of high density.Used when the clusters are irregular or intertwined, and w
18、hen noise and outliers are present.6 density-based clusters6/12/2010#Types of Clusters: Conceptual Clustersl Shared Property or Conceptual ClustersFinds clusters that share some common property or represent a particular concept.2 Overlapping Circles6/12/2010#Types of Clusters: Objective Functionl Cl
19、usters Defined by an Objective FunctionFinds clusters that minimize orize an objective function.Enumerate all possible ways of dividing the points into clusters and evaluate the goodness' of each potential set of clusters by using the given objective function. (NP Hard)Can have global or local o
20、bjectives.u Hierarchical clustering algorithms typically have local objectivesu Partitional algorithms typically have global objectivesA variation of the global objective function approach is to fit thedata to a parameterized mu Parameters for the m.are determined from the data.u Mixture ms assume t
21、hat the data is a mixture' of a number ofstatistical distributions.6/12/2010#Types of Clusters: Objective Function l Map the clustering problem to a different domain and solve a related problem in that domainProximity matrix defines a weighted graph, where the nodes are the points being clustere
22、d, and the weighted edges represent the proximities between pointsC3C4C1C5C26/12/2010#C1C2C3C4C5C1C2C3C4C5Types of Clusters: Objective Function Clustering is equivalent to breaking the graph into connected components, one for each cluster.Want to minimize the edge weight between clusters and edge we
23、ight within clustersize the6/12/2010#Characteristics of the Input Data Are Importantl Type of proximity or density measureThis is a derived measure, but central to clusteringl SparsenessDictates type of similarityAdds to efficiencyl Attribute typeDictates type of similarityl Type of DataDictates typ
24、e of similarityOther characteristics, e.g., autocorrelationl Dimensionalityl Noise and Outliersl Type of Distribution6/12/2010#Clustering Algorithmsl K-means and its variantsl Hierarchical clusteringl Density-based clustering6/12/2010#K-means ClusteringPartitional clustering approachEach cluster is
25、associated with a centroid (center point)Each point is assigned to the cluster with the closest centroidNumber of clusters, K, must be specifiedThe basic algorithm is very simplelllll6/12/2010#K-means Clustering DetailsInitial centroids are often chosen randomly.lClusters produced vary from one run
26、to another.The centroid is (typically) the mean of the points in thecluster.Closeness is measured by Euclidean distance, cosine similarity, correlation, etc.K-means will converge for common similarity measures mentioned above.Most of the convergence happens in the first few iterations.llllOften the
27、stopping condition is changed to Until relatively few points change clustersComplexity is O( n * K * I * d )ln = number of points, K = number of clusters,I = number of iterations, d = number of attributes6/12/2010#Two different K-means Clusterings32.5Original Points21.510.50-2-1.5-1-0 50x0.511.52332
28、.52.5221.51.5110.50.500-2-1 5-1-0.50x0.511.52-2-1 5-1-0.50x0.511.52Optimal ClusteringSub-optimal Clusteringyyy6/12/2010#Importance of Choosing Initial CentroidsIteration 632.521.510.50-2-1 5-1-0.50x0.511.52y6/12/2010#Importance of Choosing Initial CentroidsIterationIterationIteration3332.52.52.52221
29、.51.51.51110.50.50.5000-2-1 5-1-0.50x0.511.52-2-1 5-1-0.50x0.511.52-2-1 5-1-0.50x0.511.52IterationIterationIteration 63332.52.52.52221.51.51.51110.50.50.5000-2-1 5-1-0.50x0.511.52-2-1 5-1-0.50x0.511.52-2-1 5-1-0.50x0.511.52yyyyyy6/12/2010#Evaluating K-means Clustersl Most common measure is Sum of Sq
30、uared Error (SSE)For each point, the error is the distance to the nearest clusterTo get SSE, we square these errors and sum them.KååSSE =2dist (m , x)ii=1 xÎCix is a data point in cluster Ci and mi is the representative point for cluster Ciu can show that mi corresponds to the center
31、(mean) of the cluster Given two clusterings, we can choose the one with the smallest errorOne easy way to reduce SSE is to increase K, the number of clustersu A good clustering with smaller K can have a lower SSE than a poorclustering with higher K6/12/2010#Importance of Choosing Initial Centroids I
32、teration 532.521.510.50-2-1 5-1-0.50x0.511.52y6/12/2010#Importance of Choosing Initial Centroids IterationIteration332.52.5221.51.5110.50.500-2-1 5-1-0.50x0.511.52-2-1 5-1-0.50x0.511.52IterationIterationIteration 53332.52.52.52221.51.51.51110.50.50.5000-2-1 5-1-0.50x0.511.52-2-1 5-1-0.50x0.511.52-2-
33、1 5-1-0.50x0.511.52yyyyy6/12/2010#Problems with Selecting Initial PointsIf there are K real clusters then the chance of selecting one centroid from each cluster is small.lChance is relatively small when K is largeIf clusters are the same size, n, thenFor example, if K = 10, then probability = 10!/10
34、10= 0.00036Sometimes the initial centroids will readjust themselves inright way, and sometimes they dontConsider an example of five pairs of clusters6/12/2010#10 Clusters ExampleIteration 486420-2-4-60510x1520Starting with two initial centroids in one cluster of each pair of clustersy6/12/2010#10 Cl
35、usters ExampleIterationIteration8866442200-2-2-4-4-6-60510152005101520xxIterationIteration 48866442200-2-2-4-4-6-60510x15200510x1520Starting with two initial centroids in one cluster of each pair of clustersyyyy6/12/2010#10 Clusters ExampleIteration 486420-2-4-60510x1520Starting with some pairs of c
36、lusters having three initial centroids, while other have only one.y6/12/2010#10 Clusters ExampleIterationIteration8866442200-2-2-4-4-6-60510Iteration15200510Iteration 415208866442200-2-2-4-4-6-60510x15200510x1520Starting with some pairs of clusters having three initial centroids, while other have on
37、ly one.yyyy6/12/2010#Solutions to Initial Centroids Probleml Multiple runsHelps, but probability is not on your sidel Sample and use hierarchical clustering to determine initial centroidsl Select more than k initial centroids and then select among these initial centroidsSelect most widely separatedl
38、 Postprocessing fixup the set of clusters producedl Bisecting K-meansNot as susceptible to initialization issues6/12/2010#Handling Empty Clustersl Basic K-means algorithm can yield empty clustersl Several strategiesChoose the point that contributes most to SSEu farthest away from any current centroi
39、dChoose a point from the cluster with the highest SSEu typically split the clusterIf there are several empty clusters, the above can be repeated several times.6/12/2010#Updating Centers Incrementallyl In the basic K-means algorithm, centroids are updated after all points are assigned to a centroidl
40、An alternative is to update the centroids after each assignment (incremental approach)Each assignment updates zero or two centroids More expensiveIntroduces an order dependencyNever get an empty cluster (产生空簇)Can use “weights” to change the impact6/12/2010#Pre-processing and Post-processingl Pre-pro
41、cessingNormalize the dataEliminate outliersl Post-processingEliminate small clusters that may represent outliersSplit loose clusters, i.e., clusters with relatively high SSEMerge clusters that are close and that have relatively low SSECan use these steps during the clustering processu ISODATA6/12/20
42、10#Bisecting K-meansBisecting K-means algorithmlVariant of K-means that can produce a partitional or a hierarchical clustering6/12/2010#Bisecting K-means Example6/12/2010#Limitations of K-meansl K-means has problems when clusters are of differingSizes DensitiesNon-globular shapesl K-means has proble
43、ms when the data contains outliers.6/12/2010#Limitations of K-means: Differing SizesK-means (3 Clusters)Original Points6/12/2010#Limitations of K-means: Differing DensityK-means (3 Clusters)Original Points6/12/2010#Limitations of K-means: Non-globular ShapesOriginal PointsK-means (2 Clusters)6/12/20
44、10#Overcoming K-means LimitationsOriginal PointsK-means ClustersOne solution is to use many clusters.Find parts of clusters, but need to put together.6/12/2010#Overcoming K-means LimitationsOriginal PointsK-means Clusters6/12/2010#Overcoming K-means LimitationsOriginal PointsK-means Clusters6/12/201
45、0#Hierarchical Clusteringl Produces a set of nested clusters organized as a hierarchical treel Can be visualized as a dendrogram (树状图)A tree like diagram that records the sequences of merges or splits560.243420.15520.110.051301325466/12/2010#Strengths of Hierarchical Clusteringl Do not have to assum
46、e any particular number of clustersAny desired number of clusters can be obtained by cutting the dendogram at the proper levell They may correspond to meaningful taxonomiesExample in biological sciences (e.g., animal kingdom, phylogeny reconstruction, )6/12/2010#Hierarchical Clusteringl Two main typ
47、es of hierarchical clusteringAgglomerative:u Start with the points as individual clustersu At each step, merge the closest pair of clusters until only one cluster (or k clusters) leftDivisive:u Start with one, all-inclusive clusteru At each step, split a cluster until each cluster contains a point (or there are k clusters)l Traditional hierarchical algorithms use a similarity or distance matrixMerge or split one cluster at a time6/12/2010#Agglomerative Clustering AlgorithmMore popular hierarchical clustering techniqueBasic algorithm is straightforwardll1.
温馨提示
- 1. 本站所有资源如无特殊说明,都需要本地电脑安装OFFICE2007和PDF阅读器。图纸软件为CAD,CAXA,PROE,UG,SolidWorks等.压缩文件请下载最新的WinRAR软件解压。
- 2. 本站的文档不包含任何第三方提供的附件图纸等,如果需要附件,请联系上传者。文件的所有权益归上传用户所有。
- 3. 本站RAR压缩包中若带图纸,网页内容里面会有图纸预览,若没有图纸预览就没有图纸。
- 4. 未经权益所有人同意不得将文件中的内容挪作商业或盈利用途。
- 5. 人人文库网仅提供信息存储空间,仅对用户上传内容的表现方式做保护处理,对用户上传分享的文档内容本身不做任何修改或编辑,并不能对任何下载内容负责。
- 6. 下载文件中如有侵权或不适当内容,请与我们联系,我们立即纠正。
- 7. 本站不保证下载资源的准确性、安全性和完整性, 同时也不承担用户因使用这些下载资源对自己和他人造成任何形式的伤害或损失。
最新文档
- 专利申请居间合同模板
- 神经内科年终工作总结
- 脑血管介入手术护理配合
- 北京市2025年度家具仓储租赁与品牌推广合作协议
- 简易保险代理居间合同
- 2024浙江省瑞安市塘下职业中等专业学校工作人员招聘考试及答案
- 2024年九月煤炭堆场周边野生动物防护设施租赁合同
- 办公用房租赁合同范本(甲乙丙三方)
- 黄金首饰采购合同
- 秩序员岗位规范
- 民宿的经营成本分析报告
- 2025 预应力混凝土钢管桁架叠合板
- 2025年上海青浦新城发展(集团)限公司自主招聘9名高频重点提升(共500题)附带答案详解
- 废酸处置合同协议
- 2024年吉安职业技术学院单招职业技能测试题库附答案
- 湖南省对口招生考试医卫专业试题(2024-2025年)
- 公共危机管理(本)-第五次形成性考核-国开(BJ)-参考资料
- 《高致病禽流感现状》课件
- 中建项目移动式操作平台施工方案
- 高级职称(副高)护理学考点秘籍
- 2023年贵州省中学生生物学竞赛考试(初赛)试题
评论
0/150
提交评论